Welcome!
This page serves as an informal complement to the original publication about the framework (currently under review) and the included documentation.
Table of contents
- Introduction & installation
- What it does
- Transparency, Flexibility
- Overview and test-run
- Modeling procedures
- Performance evaluation
- Extracting and presenting results
- Big data computations
Introduction
Drew Conway put his finger on what data science essentially is in a venn diagram I like very much.
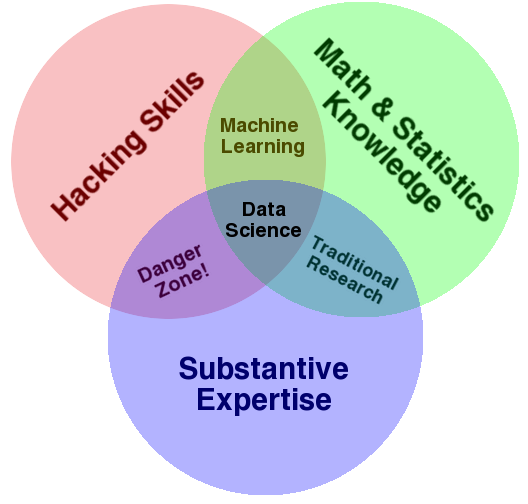
Meaning, when tackling a new classification, regression, or survival analysis problem you rarely manage to find a ready-to-use-tool that is both perfectly adapted to the situation at hand and just works out of the box. Typically, you add some additional filtering or feature selection, use a custom kernel or regularization term, or maybe even implement your own classification algorithm from scratch. When running it you spend quite some time debugging it, setting up a resampling procedure for testing how good it is, and then debug it again when it goes crazy on some data that doesn't look like you expected it would. In other words, you hack together a solution, and can actually save a lot of by not re-inventing the wheel from scratch.
Get it installed and let me show you how! The lastest official release of the emil package can be downloaded from CRAN.
install.packages("emil")
Or if you are curious on the lastest development version it can be installed directly from GitHub with the devtools package.
What it does
Lipsum lipsum
Transparency, Customization, and Debugging
Emil is designed to help you through this process. It provides a flexible boiler plate for the analysis that takes care of the tedious but straight-forward book-keeping aspects (like resampling and parameter tuning), but at the same time let's you change or reimplement anything that isn't to your liking. At the same time it doesn't add any noticable computational burden and a lot of development time. and allow you to evaluate your complete .
To get the most out of your data when doing predictive modeling, it is crucial to adapt the modeling to the application at hand. Typically you end up with custom filterings, distance or kernel functions, regularization Emil, short for evaluation of modeling without information leakage, is designed to be a flexible backbone of predictive modeling analyses that allows the user to quickly implement and test any kind of method.